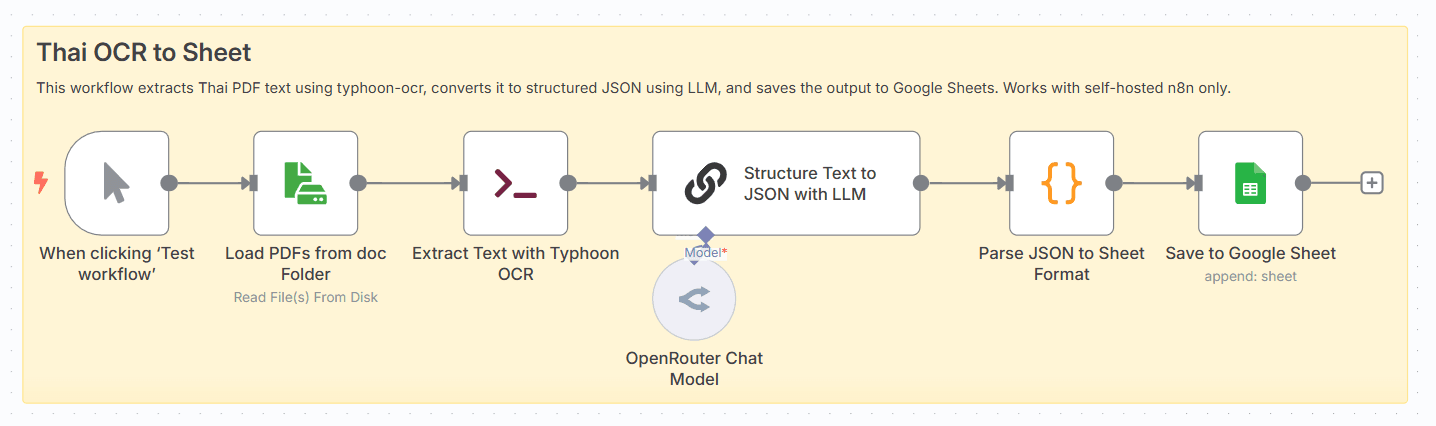
⚠️ Note: This template requires a community node and works only on self-hosted n8n installations. It uses the Typhoon OCR Python package and custom command execution. Make sure to install required dependencies locally.
This template is for developers, operations teams, and automation builders in Thailand (or any Thai-speaking environment) who regularly process PDFs or scanned documents in Thai and want to extract structured text into a Google Sheet.
Typhoon OCR is one of the most accurate OCR tools for Thai text. However, integrating it into an end-to-end workflow usually requires manual scripting and data wrangling.
doc/ foldertyphoon-ocr: pip install typhoon-ocrpdftoppm, pdfinfo)doc in the same directory where n8n runs (or mount it via Docker)Create a Google Sheet with the following column headers:
| book_id | date | subject | detail | signed_by | signed_by2 | contact | download_url |
|---|
You can use this example Google Sheet as a reference.
Export your TYPHOON_OCR_API_KEY and OPENAI_API_KEY in your environment (or set inside the command string in Execute Command node).
Basic LLM Chain node (currently supports OpenRouter)Typhoon is a multilingual LLM and toolkit optimized for Thai NLP. It includes typhoon-ocr, a Python OCR library designed for Thai-centric documents. It is open-source, highly accurate, and works well in automation pipelines. Perfect for government paperwork, PDF reports, and multilingual documents in Southeast Asia.